On this page
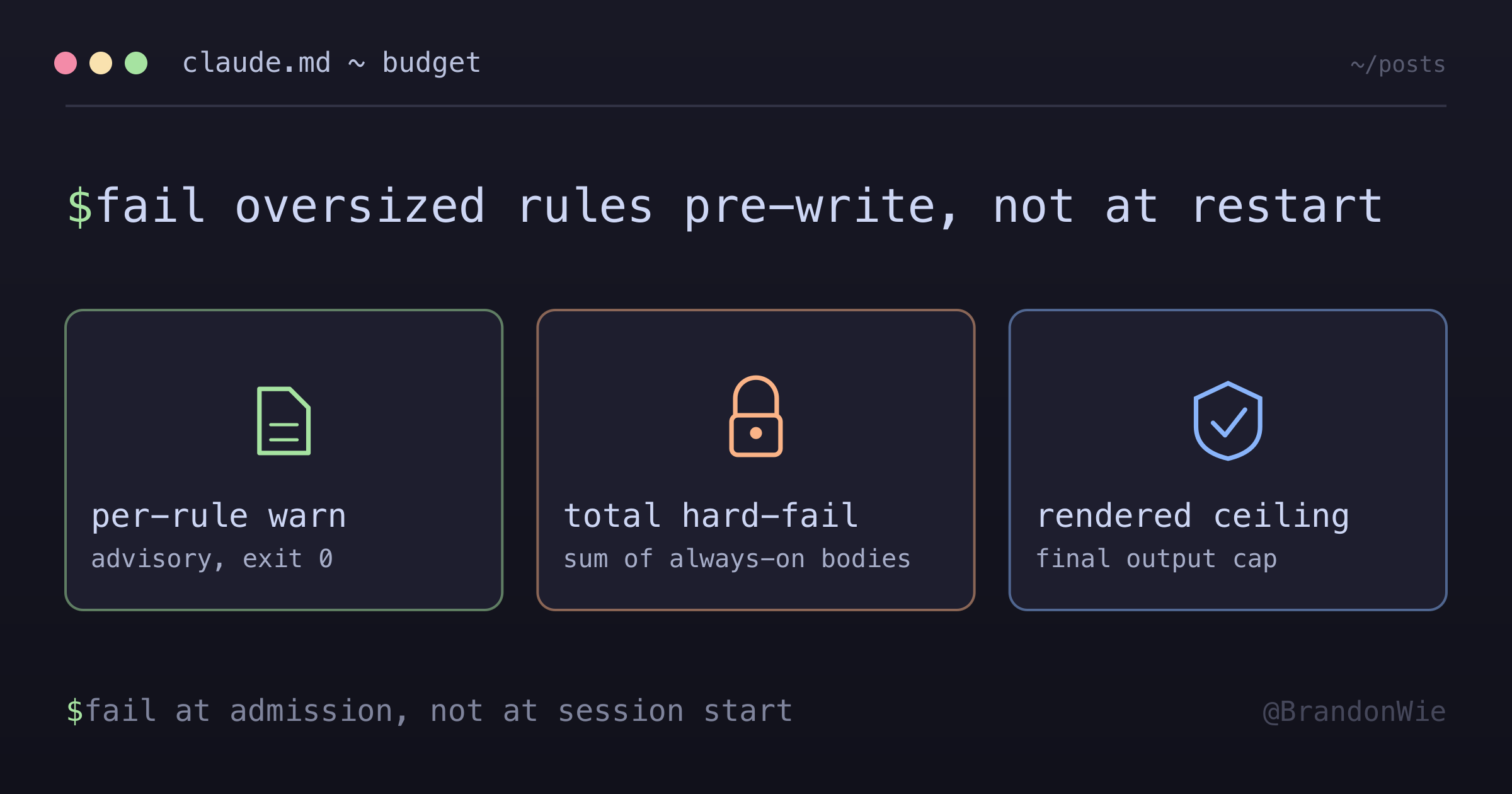
When CLAUDE.md keeps overflowing, move the budget into your generator
The "Large CLAUDE.md will impact performance" warning kept coming back weeks after every trim. It stopped for good once the byte budget moved out of author discipline and into the generator that assembles the file — as a per-rule warning, a total hard-fail, and a rendered-file ceiling.
Agent tools that load an always-on context file — Claude Code’s CLAUDE.md,
Codex’s AGENTS.md, Gemini’s GEMINI.md — put that file into every session’s context window.
That’s the point of it, and it’s also a finite budget. Claude Code shows a
session-start performance warning once the file gets large; in my setup I started
seeing “Large CLAUDE.md will impact performance” around 40,000 characters.
I trimmed the file, the warning went away, and a few weeks later it was back. I trimmed again. Same result. After the second round I stopped trimming and went looking for why a file I’d just shrunk kept regrowing past the line.
Why author discipline wasn’t enough
My CLAUDE.md isn’t hand-written. A generator assembles it from a set of rule
files, inlining the ones I’ve marked as always-on into an auto-generated block.
That structure is exactly why discipline failed: every edit to an always-on rule
nudges the total a little, no single edit looks like the problem, and nobody sees
the cumulative size while editing one rule. The only feedback is the performance
warning — and that surfaces at session start, often days after the edit that
pushed it over. A one-off trim bought margin; the next wave of “let’s make this
rule always-on” opt-ins quietly ate the margin again, and the warning came back
two weeks later like clockwork.
So the real problem wasn’t “the file is too big right now.” It was “regressions are caught at session start instead of at the moment they’re introduced.” I wanted the budget enforced at admission time — when a rule gets added or grows — not after the next restart.
The dead ends
The obvious fix is a hard per-rule cap: refuse any single always-on rule above N bytes. It doesn’t survive contact with reality. My largest legitimate always-on rule is around 7.3 KB and is locked behind an off-limits boundary I couldn’t restructure, so a 5 KB per-rule cap would just block itself — the gate fails on a rule it can’t fix. And even a working per-rule cap misses the actual failure mode, which is cumulative: ten rules each comfortably under the cap still add up to an over-budget file.
There was also a misleading signal that cost me a debugging loop: my pre-commit hook ran a formatter after the generator, so the generator would emit clean output, the formatter would reflow it, and the next run would see “drift” and complain. The fix to the budget was tangled up with fixing that ordering first.
Three gates, because there are three regression vectors
What actually held up was treating the budget as three separate checks, each catching a different way the file grows:
- a per-rule advisory warning, so an oversized rule announces itself without blocking the commit;
- a total hard-fail on the sum of always-on bodies, which is the cumulative regrowth the per-rule check can’t see;
- a rendered-file ceiling on the final output, which catches hand-edited growth in the header/tail that lives outside the generated block and is invisible to the other two.
All three run pre-write, so a bad state never lands on disk in the first place. In my generator that’s three constants and two validation blocks:
const UNIVERSAL_RULE_WARN_BYTES = 5000; // per-rule advisory (stderr WARN, exit 0)
const UNIVERSAL_TOTAL_MAX_BYTES = 30000; // sum of always-on bodies — hard fail
const CLAUDE_TEMPLATE_MAX_BYTES = 38000; // rendered file — hard faillet totalBytes = 0;
const offenders = [];
for (const r of alwaysOnRules) {
const size = Buffer.byteLength(r.body, "utf8");
totalBytes += size;
if (size > UNIVERSAL_RULE_WARN_BYTES) {
process.stderr.write(
`[gen] WARN ${r.file} body ${size}b > ${UNIVERSAL_RULE_WARN_BYTES} ` +
`(advisory; consider splitting or making it lazy-load)
`
);
}
offenders.push({ file: r.file, size });
}
if (totalBytes > UNIVERSAL_TOTAL_MAX_BYTES) {
offenders.sort((a, b) => b.size - a.size);
const top3 = offenders.slice(0, 3).map((o) => ` - ${o.file}: ${o.size}b`).join("
");
throw new Error(
`[gen] always-on total ${totalBytes}b > ${UNIVERSAL_TOTAL_MAX_BYTES} budget.
` +
`Top offenders:
${top3}
Remediate: make a rule lazy-load.`
);
}// Before writing the rendered file:
const renderedBytes = Buffer.byteLength(rendered, "utf8");
if (renderedBytes > CLAUDE_TEMPLATE_MAX_BYTES) {
throw new Error(
`[gen] rendered ${renderedBytes}b > ${CLAUDE_TEMPLATE_MAX_BYTES} ceiling ` +
`(tool warns around 40000). No write performed.`
);
}The numbers are mine, not universal: the total cap matches the sum of always-on
bodies I actually carry, and the rendered ceiling sits a few KB under the warning
threshold so there’s margin for the wrapper text. The point isn’t the constants —
it’s that a throw here is enough, because my pre-commit hook already runs the
generator and propagates a non-zero exit as a blocked commit. No new hook
plumbing; the generator failing is the gate.
A couple of small traps if you build this yourself. The per-rule WARN has to be
advisory (exit 0) or every slightly-large-but-legitimate rule blocks your commit
and you’ll reach for the bypass flag, which defeats the whole thing. And watch
your field names when you sum sizes — I spent real time on a Buffer.byteLength(undefined) because I’d read the wrong property off the rule
object, and the error was generic enough to chase in the wrong direction.
What it bought
After wiring it in, my always-on file landed around 35 KB — roughly 5 KB under the warning threshold, with the over-budget state coming from three rules that were always-on but didn’t need to be. I made those lazy-load (fetched on demand instead of inlined) and kept them always-on for the other agents whose budgets weren’t at the cliff, since each tool’s budget is independent. The warning hasn’t come back, because the next time something pushes the total over, the commit that introduces it fails instead of a session three days later.
When this is worth it (and when it isn’t)
It pays off when an always-on context surface is assembled from many pieces by multiple contributors who don’t coordinate size, and when you’ve seen the trim-then-regrow cycle at least once. If your file is hand-written by one person who sees the whole thing on every edit, the visual feedback is already your gate. And if your rules are lazy-loaded rather than always inlined, the budget is per-fetch, not cumulative, so there’s nothing to total up. The one combination to avoid is a per-item check alone — without a total gate or a rendered ceiling, the cumulative and out-of-band growth both walk right past it.
The takeaway
When a generated, always-on file keeps overflowing, the fix usually isn’t another trim — it’s moving the budget from author discipline into the generator, and enforcing it pre-write so regressions fail at admission time instead of at the next session start. Pair a per-item signal with a total gate, because the failure mode that actually bites is the one no single edit looks responsible for.